深度学习优化器Optimizer总结-tensorflow-1原理篇
本文共 1728 字,大约阅读时间需要 5 分钟。
单纯以算法为论,深度学习从业者的算法能力可能并不需要太大,因为很多时候,只需要构建合理的框架,直接使用框架是不需要太理解其中的算法的。但是我们还是需要知道其中的很多原理,以便增加自身的知识强度,而优化器可能正是深度学习的算法核心
本文基本完全参考以下连接:
原理简化讲解篇: 使用经验篇: 优化器tensorflow官方文档:官方文档所给的优化器很多,而且后续也在不停地添加当中,因此,我这里只列举基础和常用的几个:
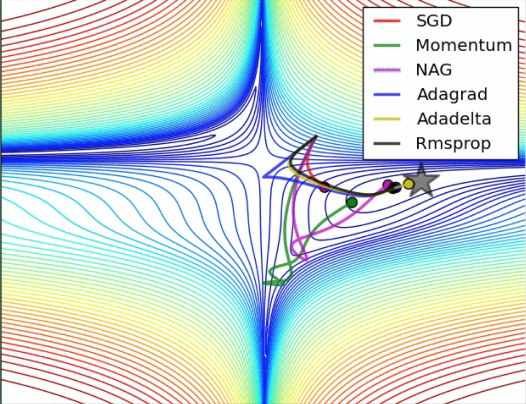 优化器分类:
优化器分类: -
Stochastic Gradient Descent (SGD):随机梯度,分批,随机放入一批,而不是全部放入,加快训练速度,却不会大大影响效果
-
Optimizer 主类:
- GradientDescentOptimizer :实现梯度下降算法的优化器。(结合理论可以看到,这个构造函数需要的一个学习率就行了)
- MomentumOptimizer Momentum单词即动量、动力,这里的意思可以理解为惯性,想象一下,如果你现在从山上玩下冲,你的目的是到达最低点,但是如果这个山坡并不是直线梯度下降,而是局部左拐右拐梯度下降,这样将导致下降步骤是个折线形,大大降低训练速度,这也是基本梯度下降算法的缺点,因此这里引入了动量因子。 所以你下山有之前的动量,即便你想拐弯都拐不了很大 比如:原来的梯度计算是:variable -= learning_rate * gradient; 现在变为:variable -= learning_rate * (momentum * accumulation + gradient) 这里的momentum * accumulation是之前的动量积累,所以就导致即便局部有折线,也会由于之前的动量影响太大,而尽量保持直线下降 源码公式: accumulation = momentum * accumulation + gradient variable -= learning_rate * accumulation 或者直接是:W += b1 * m -Learning rate * dx
- AdagradOptimizer 公式变化如下: W += -Learning rate * dx 变为: v += dx^2 W += -Learining rate * dx /sqrt(v) ada-即单词Adaptive,中文:自适应 同增加惯性因子的原理类似,此方法也是为了减轻局部偏折,但是作用在学习率上。即为了防止偏折过大,我们会首先计算偏折幅度-即梯度值,并将其作为学习率分母参数。意思就是,如果梯度很大,学习率就很低,这样防止偏折过大;梯度很小,学习率就大。
- AdagradDAOptimizer 略
-
RMSPropOptimizer
AdaGrad阻力因子考虑了当前的梯度,并没有考虑之前的梯度系数,这样会导致不管是迭代100次的或者是迭代10000次的,阻力都是一样的,没有区别。如果是运行到接近最优化处,其实阻力应该更大一些,因为此时只需要微调就行,所以这里增加了一个全局梯度累计,这样,梯度阻力会随着迭代的次数不断增大。 可能做到的改进:AdaGrad阻力因子没有考虑一个特殊情况,即如果下山最大梯度确实有个很大的90度折线,而且这个折线正是全局梯度方向,但是由于这个阻力因子的存在,可能每次梯度都很大,每次都阻碍,反而降低了下降速度,所以,这里可以添加了一个占比系数,即不仅仅考虑当前的梯度值,而且还要考虑之前的梯度值,这样,当梯度值一直很大时,说明可能是对的道路,阻力相应就减小。 公式: V = b2* V +(1-b2) * dx^2 W += -Learining rate * dx /sqrt(v) -
AdamOptimizer
Adam联合了momentum 的惯性原则 , 加上 adagrad 的对错误方向的阻力 公式: M += b1 * m -Learning rate * dx (momentum) V = b2* V +(1-b2) * dx^2 (AdaGrad) W += -Learining rate * M /sqrt(V)
转载地址:http://aeepi.baihongyu.com/
你可能感兴趣的文章
pytorch(三)
查看>>
pytorch(5)
查看>>
ubuntu相关
查看>>
C++ 调用json
查看>>
nano中设置脚本开机自启动
查看>>
动态库调动态库
查看>>
Kubernetes集群搭建之CNI-Flanneld部署篇
查看>>
k8s web终端连接工具
查看>>
手绘VS码绘(一):静态图绘制(码绘使用P5.js)
查看>>
手绘VS码绘(二):动态图绘制(码绘使用Processing)
查看>>
基于P5.js的“绘画系统”
查看>>
《达芬奇的人生密码》观后感
查看>>
论文翻译:《一个包容性设计的具体例子:聋人导向可访问性》
查看>>
基于“分形”编写的交互应用
查看>>
《融入动画技术的交互应用》主题博文推荐
查看>>
链睿和家乐福合作推出下一代零售业隐私保护技术
查看>>
Unifrax宣布新建SiFAB™生产线
查看>>
艾默生纪念谷轮™在空调和制冷领域的百年创新成就
查看>>
NEXO代币持有者获得20,428,359.89美元股息
查看>>
Piper Sandler为EverArc收购Perimeter Solutions提供咨询服务
查看>>